Tutorial 0: Neural Networks Intro
-
Author: Brian A. Ree
1: Neural Networks
So you want to learn about neural networks? Well let's take a crash course and dive in. Biological brains have puzzled scientists
for quite some time because they are able to perform complex tasks with relatively low powered, simple brains. Large, powerful
computers running at frequencies far above the biological brain's rythms can't compete with the ability of even a simple animal brain
in terms of pattern recognition, learning, navigation, etc. And a simple animal brain can do all of that and more. So what gives?
How can these simple brains learn so quickly and recognize patterns so easily compared to very powerful computers? Let's find out.
Scientists began to focus more on the differences between biological brains and computers. Not in their physical construcution per say but in the
way they process information, in an abstract sense. Computers process information sequentially and in discreet states, 0's and 1's.
Not much room for fuzzy logic as you can see.
Biological brains process information in parallel and in terms that are almost always fuzzy. So how can simple bio-brains process information in such
a way that complex tasks like pattern information in such a way that complex tasks like pattern recognition and learning seem so easy? Scientists beleive
that neural networks in bio-brains compute information very differently, they seem to solve problems as a network. This is a very different approach from the
rigid, discreet states of computers.
As you may have guessed by now the main component in a neural network, artificial or biological, is a neuron. While we won't go into the biology of neurons
we will describe them in simple terms. Neurons take in electrical signals and pop out electrical signals but they don't fire out those electrical signals in a
way that you would expect. Some inputs are ignored, in some cases all input is ignored. In other words there is some threshold that must be reached by the input signals
before the neuron sends an output signal. This sounds reasonable, it's how neurons in our brains pass information to each other, using electrical signals. We can think about modeling
this in code on a computer and replacing the electrical signals with numbers.
So let's represent a neuron's activation behavior with a mathematical function, after all it almost sounds like we're talking about functions when we mention input and output, no?
What kind of function could we use? Let's think about a linear function, after all this is the simplest kind of function. A good first guess but no, neurons don't always fire on input
so they don't really fit the pattern of a linear function. A linear function would be bad at surpressing some input and firing after a threshold is reached by the input signals.
Let's try another type of function, something with more of an 'activation' feel to it. I'll supply one for us to look at.
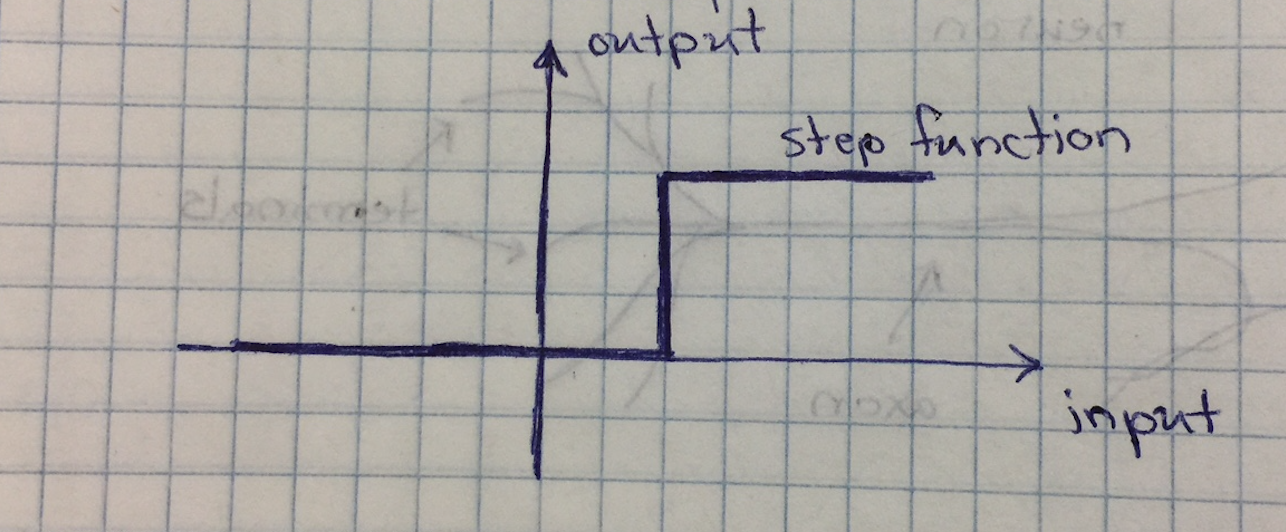
This is an example of a step function. A quick look over the function and we can see that there is something of a threshold and so it can act as an
activation function. For low input values, think x-axis, the strp function surpresses the output, y-axis is at zero. After a certain input value however
the function starts abruptly starts to return a value and continues to return that value for all subsequent, larger inputs. It is closer to what we want
but take a look at the graph of the step function again, does anything stand out? It is very binary and rigid don't you think.
Omg, did yu just notice what we did? We just made a decision based on feelings, pattern matching, and observation, we made a fuzzy logic decision.
Now let's find another activation function that can help us write a neural network that can handle some fuzzyness.
Others have done the work for us and wereniceenough to share it so let's look at a function you may not have known about.
It is called a sigmoid function, looks kind of like a stretched version of the step function. It is smoother and more natural than
the binary step function. This new activation function definitely looks like it can have some fuzziness. What's more this is a common function
in certain areas of math, it is well known, and easy to use in calculation than some other similar functions. All that sounds good to me, so let's
use a sigmoid activation function.
Now that we have our activation function, we'll skip over the heavy maths and let python and numpy take care of that for us in this tutorial.
Let's figure out how we can model a neuron. Let's say neurons take many inputs, this is a fair assumption, I'm not a brain surgeon but I stayed at a
holiday inn express recently. If the sum of the inputs is greater that the threshold then our neuron fires.
Let's say we have four inputs to our neuron. Think of all the different ways values the four inputs could have such that the sum of the inputs matches the
neurons activation threshold. One very strong input, two semi strong inputs, one strong input and a weak input, four moderate inputs, etc. You can see
how fuzzy it can get, how flexible it can be.
We can also assume that the outputs to neurons may be many and may route to many other neurons. Again I'm just going on instinct
here but you'll soon see that an excess of inter-neuron connections isn't going to affect us too much. So let's try and come up with a way to
structure our little artificial neurons. I suppose we could come up with a complex method for connecting them together in some quasi brain
layout but since we're modeling them with a computer and we intend to do some maths on them let's look for something more structured. How bout
we just lay them out on a grid. Computers are good at grids and it will play nicely with math we'll need to use, namely matrices, which are essentially
laid out in a grid for al lintensive purposes.
If we lay everything out in one giant grid then we'll only have one giant matrix, not much you can do with just one matrix
as far as neural networks are concerned. So let's take it slow and start with a column, simple grid with a few rows and only one column
because we can easily represent them with arrays or lists. One layer doesn't seem like much fun, two is better but still a little boring, how about
we use three layers of single column neurons to represent our simple neural network? Sounds good to me. Let's take a look at what it might look like below.
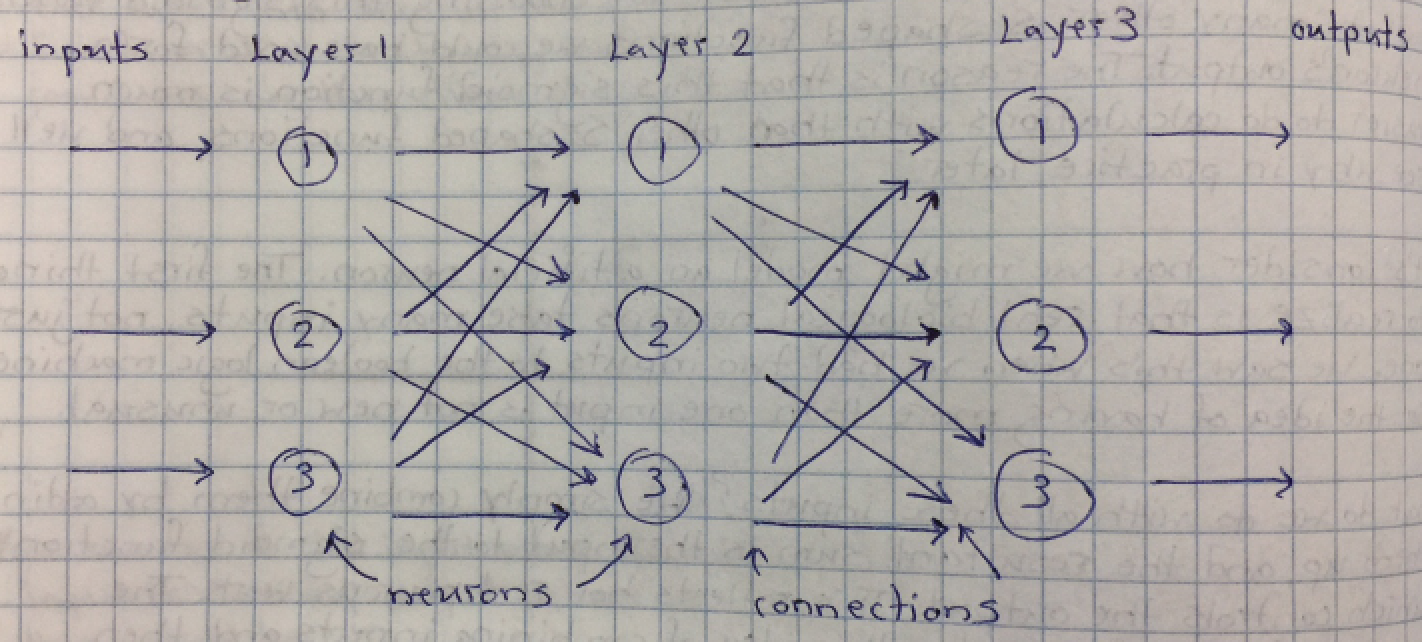
You can see the described layers in our artificial neural network. Each node is connected to the nodes in the next layer.
All the connections are assigned a weight value and the weight values will naturally diminish the importance of those
connections. Sure we could have come up with a random set of connections but then we might introduce arbitrary and unpredictable
behaviors so let's always start with a fully connected network and let our learning process take care of things for us.
Well if you asked how can the weights do this for us? An artificial neural network learns to improve it's outputs by refining the link
weights inside the network, some weights get very close to zero, weights close to zero don't controbute to the network because they
send very weak to no signals.
The next few steps are fairly complex so we are going to summarize them here in breif. In order to train our neural
network we need to pass input into the network and compare what comes out to a known correct answer for that input. To feed input
into our neural network we send signals in the form of numbers to our input neurons on the left most layer and they pass the modified output to
the next neuron layer until it reaches the output layer.
To perform this operation we have to track all the values as they pass through our artificial neurons. Wow, that sounds like a lot
of work. Worry not, we can simplify the expression and the work using matrix multiplication. Matrix multiplication is for computers
to do, within reason, and plays very nicely with our grid layer network design. When we feed input into our network we get an end result, the output.
By comparing the network's output with the known expected output we can calculate an error. Some of the details and math involved are beyond the scope
of this tutorial but the reference material mentioned it above covers it in great detail and it is very easy to understand. Our goal is to minimize this error
by training our network and exposing it to training data and known answers. Each time we push new inputs from our training data we get new outputs to compare to
our expected output, this gives us an error. To minimize this error we slowly adjust the weights in our network until the output
matches the expected output better and our error is minimized.
The technique used to adjust the internal network weights is called back propagation. Essentially we back propagate the error from the output to each
successive step along the way, but in reverse. The amount that we adjust each weight is called the learning rate because the adjustments to the weights
can be viewed as 'learning' the network is starting to take on a pattern that matches the expected output closer and closer. These small adjustments
are actually a way for use to walk along the error curve slowly moving and seeing if the error curve is getting lower, until we reach the minimum value
on the error curve. Once the minimum value is reached we have trained our network as best we can against the data and we're ready to validate.
I should mention that this is not magic, inputs that aren't related and have not pattern will results in bad error scores and output that doesn't really
make sense. Remember we're training our network to learn something, find a pattern in some data so we sort expect there to be a relationship we're trying to
discover.
I hope that clarifies things a little bit. This material is alittle abstract so we should probably use an example to show how it works.
To that end we will begin writing our own neural network from scratch in the next tutorial in this series.